Jak se migruje obrovská databáze bez výpadku
Některé úkony jsou primitivní, dokud je nepotřebujete provést na trochu větším projektu. Hezkým příkladem je třeba migrace databáze - jednoduchý úkon při velikosti 20 MB, ale daleko komplexnější pro 400 GB.
Nejjednodušší migrace
Pokud máte malou databázi a můžete si dovolit krátký výpadek, tak provedete migraci jednoduše takhle:mysqldump --single-transaction db_name | mysql --hostname='example.org' db_name
Na jedné straně se databáze vyexportuje a na druhé importuje. Nic komplikovaného. Jenže pokud je databáze velká, tak tenhle příkaz může najednou místo vteřin běžet klidně i dny. Těžko můžeme napsat klientům, že budou eshopy na víkend offline, ať jdou zatím k vodě. Tudy cesta nevede.
Přímočařejší řešení
Pokud se migruje jen mezi dvěma stroji, lze na to jít jednodušeji. Může se zastavit databázový server, překopírovat přímo datové soubory a na druhé straně spustit. Tento postup je výrazně rychlejší než import/export, ale také má svá omezení.- původní a cílový databázový server musí být stejný (tzn. třeba MySQL 5.6.26 => MySQL 5.6.26)
- musí být root přístup k serveru
- server se musí zastavit před přesunem
Komplikovaně, ale bez výpadku
Migraci jsme chtěli provést zcela bez výpadku, takže jsme celý problém vzali za úplně jiný konec. MySQL je totiž překvapivě chytré a opravdu to jde provést. Budu postup popisovat na AWS RDS, ale v principu to bude stejné i jinde.1) Zreplikujeme
Jako první krok vytvoříme read-replica k naší databázi. Tahle akce bude trvat několik hodin, ale to není problém. V případě AWS RDS je to navíc otázkou jednoho kliknutí.
Jak to funguje? Kromě našeho původního databázového serveru (master) budeme mít ještě druhý (slave). Když na master proběhne nějaká změna dat, tak o tom pošle informaci na slave a ten ji provede taky.
V eshopech tenhle postup používáme i v běžném provozu - master se používá pro zápisové akce (administrace, importy, vložení do košíku, ...) a slave pro čtecí (výpis produktů, ...). Díky tomu pak čtecí operace (kterých je většina) nevytěžují master a lze tím MySQL škálovat.

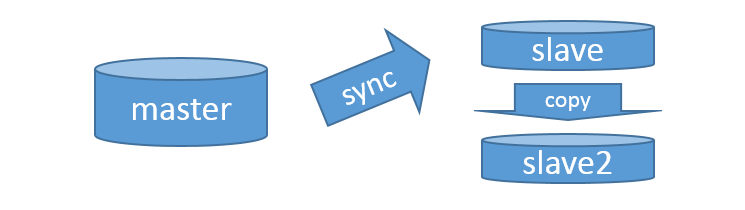
2) Zmrazíme
Po pár hodinách máme slave databázi, která se udržuje aktuální s master. S tou si teď můžeme dělat co chceme a neovlivní to provoz. Nejprve zastavíme replikaci, aby nedostávala aktuální informace od master. AWS na to má zkratkovou funkci, mimo AWS budete muset konzultovat manuál.CALL mysql.rds_stop_replication;
Tím se bude slave databáze stávat postupně stále méně aktuální - to nám ale nevadí. Dále totiž zavoláme v SQL:
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Replication stopped
Master_Host: localhost
Master_User: root
Master_Port: 3306
Connect_Retry: 3
Master_Log_File: gbichot-bin.005
Read_Master_Log_Pos: 79
Ve výstupu vidíme dvě podstatné informace - Master_Log_File a Read_Master_Log_Pos. Replikace je totiž sice vypnutá, ale pořád si pamatuje, kde přesně skončila. Pokud bychom ji znovu spustili, zeptala by se masteru, co se stalo, zatímco spala a dohnala by rozdíl.
3) Zmigrujeme
Dále replikovanou databázi zmigrujeme na nové řešení. Na ostrý provoz to nemá vliv, takže je jedno, jaký postup zvolíme. V AWS je nejjednodušší provést to přes snapshot, což je podobné jako výše popisované kopírování souborů - jen to je vyřešené během dvou kliknutí.Po zmigrování budeme mít databázi na novém řešení, ale bude mít neaktuální data.
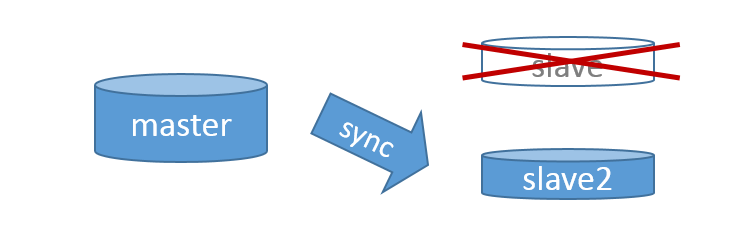
4) Zaktualizujeme
Teď naši krásnou zmigrovanou databázi přesvědčíme, že je ve skutečnosti replikou té staré - převezme tedy místo slave databáze, kterou jsme použili k jejímu vytvoření. V AWS je to zase hračka, protože na to je připravená funkce. Mimo AWS je postup v principu stejný, jen asi bude ve více krocích.CALL mysql.rds_set_external_master (
'old-master.example.org'
, 3306
, 'replication_user'
, 'replication_user_password'
, 'gbichot-bin.005' /* mysql_binary_log_file_name */
, '79' /* mysql_binary_log_file_location */
, 1 /* ssl_encryption */
);
CALL mysql.rds_start_replication;
Všimněte si, že jako parametr posíláme název log souboru a pozici v něm. Díky tomu si databáze může od master vyžádat data pro aktualizaci. Neztratí se tak ani jeden dotaz.
Aktualizace chvíli poběží - průběh můžete sledovat SQL příkazy SHOW MASTER STATUS (na masteru) a SHOW SLAVE STATUS (na slave). Postupně se budou k sobě blížit hodnoty Master_Log_File a Read_Master_Log_Pos, až budou skoro stejné.
V aktualizaci bude vždycky prodleva, takže nebudou nikdy stejné, ale prodleva bude v ideálním případě v řádu milisekund.
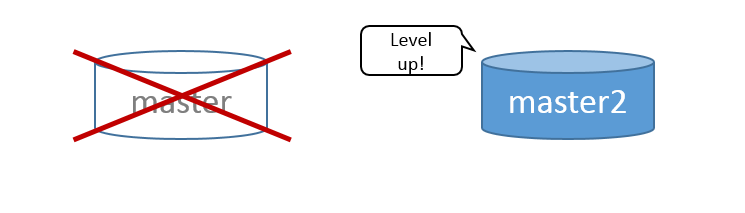
5) Přepneme
Zatím jsme nikam nespěchali a kdyby se něco nepovedlo, tak se to jen zahodí a udělá znova. Tohle už je ale poslední krok a je potřeba udělat ho napoprvé. Navíc je u něj nutná krátká odstávka, takže je ideální napsat na to skript, aby byla co nejkratší. Pro finalizaci je potřeba provést tyto úkony těsně za sebou:- zakázat zápis na master (stačí odebrat práva uživatelům)
- počkat až se synchronizuje master a slave (v ideálním případě zlomek sekundy)
- zrušit replikaci slave - stává se novým master
- přepnout provoz na nový server
Hotovo!
A to je celé. Bez větší námahy jsme zmigrovali velkou databázi. Čtení během toho nemělo žádný výpadek, zápisy měly výpadek na zlomek sekundy.Podobné akce jsou jedním z důvodů, proč se mi tak líbí v cloudu. Na tahle škatulata totiž byly potřeba tři servery. V případě klasických serverů bychom ale těžko dokupovali dva servery na jednodenní akci. U cloudu ale jen dvakrát kliknu a po stěhování je zase zahodím.
Update: Nestačí vám články? Nově nabízím i konzultace AWS cloudu :)
