Jak se programuje v cloudu
 Řešil jsem teď problém, na kterém jde krásně vidět, jak se v cloudu některé věci řeší za opačný konec než obvykle. Protože je to poměrně typický příklad, předvedu vám na něm specifika vývoje v cloudu.
Řešil jsem teď problém, na kterém jde krásně vidět, jak se v cloudu některé věci řeší za opačný konec než obvykle. Protože je to poměrně typický příklad, předvedu vám na něm specifika vývoje v cloudu.
Hostujeme eshopy v Amazonu v Irsku a ve čtvrtek byl představen nový region v Německu. Je o pár milisekund blíže, takže se tam přestěhujeme. Díky cross-region replikacím je to otázka pár kliknutí a vše lze přestěhovat zcela plynule bez výpadku. Jedinou zradou je úložiště (AWS S3). Je sice nezávislé na regionu, ale má o něco lepší odezvu, když jsou všechna data primárně ve stejném regionu. A tady přichází problém.
Velký problém
V AWS S3 máme uloženo několik TB dat. Jsou to především obrázky, ale také třeba archiv naskenovaných dokladů nebo přijatých emailů. Přenést několik TB by nebyl problém (přecijen máme 10 Gbit linku), jenže průměrný soubor má kolem 3kB. S přenosem je tak spojena obrovská režie.
Standardní postup by byl spustit si největší možnou instanci (například něco s 32 jádry), zapnout příkaz "aws s3 sync" a počkat. Vzhledem k obrovské režii by takový přenos trval minimálně dva dny. Na konci přenosu by tak data už byla neaktuální a musel by se pustit znovu. Sync sice pozná, co není třeba přenášet, ale stejně musí soubory po jednom projít.
Fun fact: Když jsme migrovali z klasických serverů do cloudu, tak toto kopírování trvalo 14 dní při polovičním objemu dat.
Spousta malých problémů
Základním postupem v cloudu je rozebrat velký problém na jeho nejmenší část. Soubory máme rozdělené ve složkách po tisících, takže místo řešení přenosu celku budeme řešit přenos složky. Přenést 1000 malých souborů se stihne pod minutu a to už je dostatečně malý problém.
Místo hledání větší instance pro zrychlení přenosu zvolíme přesně opačný postup - vezmeme malou nevýkonnou instanci, ale spustíme takových více. To je základní rozdíl mezi klasickými servery a cloudem. U serveru jsme limitování jeho maximálním výkonem, ale malých instancí můžeme v cloudu spustit kolik chceme - jejich celkový výkon bude mnohem vyšší.

Paralelní běh
Nemůžeme ale jen tak spustit stejný příkaz paralelně na více instancích. Nejprve musíme vyřešit, aby nikdy dvě instance nedělaly to samé a také aby žádná nestála bez práce. V tom nám pomůže AWS SQS (už jsem o něm psal). Do něj můžeme poslat zprávy, které se seřadí do fronty. Instance si pak z fronty můžou zprávy odebírat a SQS vyřeší zámky, mazání záznamů atd.
Složky jsou číslované podle auto_increment, takže jednoduše stačí vzít nejvyšší ID, vydělit tisícem a v primitivním cyklu vygenerujeme seznam úloh:
$client = Aws\Sqs\SqsClient::factory(array('region' => Aws\Common\Enum\Region::EU_WEST_1));
for($i=0;$i<=$maxId/1000;$i++){
$client->sendMessage(array(
'QueueUrl' => $sqsUrl,
'MessageBody' => "aws s3 sync s3://old/$i/ s3://new/$i/",
));
}
Každý příkaz uložíme do SQS jako samostatnou zprávu. Frontě pak nastavíme, že po stáhnutí zprávy má počkat 5 minut, než stejnou zprávu může stáhnout jiná instance. Pokud instance zpracuje příkaz v pořádku, mělo by to být vždy rychleji než za 5 minut a zprávu z fronty po úspěšném dokončení odmaže. Pokud by ale došlo k problému, tak si příkaz vezme ke zpracování jiná instance. Frontě také nastavíme, aby přesouvala zprávy, které nebyly smazány po 10ti staženích do separátní fronty. V té můžeme prověřit, v čem byl problém.
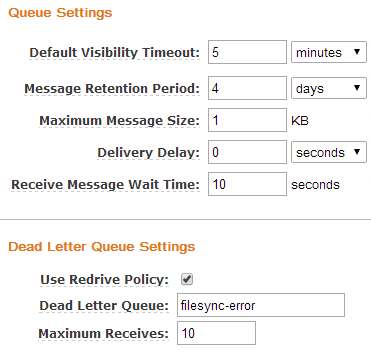
Instance
Nastartujeme instanci a nakonfigurujeme její běh. Upstart skript zajistí, že se po spuštění instance provede kopírovací skript. Pokud by z nějakého důvodu spadl, tak ho upstart restartuje. A co bude skript dělat?
- stáhne si příkaz z fronty (tím ho na 5 minut zablokuje pro jiné instance)
- spustí příkaz - provede sync jedné složky (1000 souborů)
- odmaže příkaz z fronty
- vrátí se do bodu 1.
php
$client = Aws\Sqs\SqsClient::factory(array(
'region' => Aws\Common\Enum\Region::EU_WEST_1,
// credentials se načtou z IAM profilu instance
));
while(true){
$client->receiveMessage(array(
'QueueUrl' => $sqsUrl,
'MaxNumberOfMessages' => 1, // pracovat po jedné zprávě
))->toArray();
foreach ($res['Messages'] as $m) {
exec($m['Body'], $x, $status);
if($status == 0){
// mazat z fronty jen v případě úspěšného kopírování
$client->deleteMessage(array(
'QueueUrl' => $sqsUrl,
'ReceiptHandle' => $m['ReceiptHandle'],
));
}
}
Cpát něco ze vstupu přímo do exec samozřejmě není zrovna best-practice. Tady ale máme naprostou kontrolu nad vstupem a navíc to je jednorázový skript. Nemluvě o tom, že na instanci nic kromě tohoto skriptu není.
Startujeme
Pro řízení běhu použiju autoscaling. Není tu úplně nutný, ale snadno se ním bude běh ovládat. Použiju instanci velikosti m3.medium, která by měla pro tento úkol víc než dostačovat. Nehodlám ale platit plnou cenu, takže použiju spot instanci (už jsem o nich psal). U té je cena zhruba pětinová, ale je u ní neustále riziko, že se může kdykoliv vypnout či restartovat. Náš návrh s tím ale počítá a v takovém případě se vůbec nic nestane. Pokud navíc Amazon instanci vypne, tak se načatá hodina neúčtuje (ne že by nás to při ceně $0.01/hod vytrhlo).
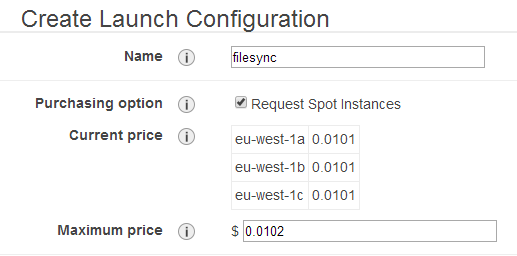
V autoscaling skupině si nastavím, že chci minimálně 32 instancí. Na každé instanci běží paralelně zhruba 6 přenosů, takže to znamená 192 paralelních přenosů při celkové ceně 7 Kč za hodinu. Pokud budu chtít v průběhu snížit počet instancí, tak jen změním číslo a je hotovo. Běh to nijak nenaruší a vypne se instance, která má nejblíž k celé hodině běhu (AWS účtuje započaté hodiny).
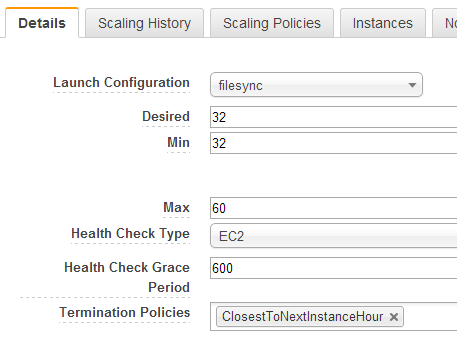 Pro autoscaling nastavíme jediné pravidlo - až nebude ve frontě žádná zpráva, tak vypnout všechny instance. Šlo by případně nastavit, aby se vypínaly postupně, když počet zpráv klesá nebo třeba nejsou dostatečně vytížené, ale to tady bude nejspíš zbytečné.
Pro autoscaling nastavíme jediné pravidlo - až nebude ve frontě žádná zpráva, tak vypnout všechny instance. Šlo by případně nastavit, aby se vypínaly postupně, když počet zpráv klesá nebo třeba nejsou dostatečně vytížené, ale to tady bude nejspíš zbytečné.
Cloud FTW
 Během chvíle jsem si vyrobil šílenou infrastrukturu přenášející objem, kterého bych s jedním serverem nikdy nedosáhl. Kdyby ale bylo potřeba, klidně by to mohlo přenášet 100x více. Jediným omezením je tu rychlost úložiště a AWS S3 je na takové věci stavěné, takže limitu není zrovna snadné dosáhnout.
Během chvíle jsem si vyrobil šílenou infrastrukturu přenášející objem, kterého bych s jedním serverem nikdy nedosáhl. Kdyby ale bylo potřeba, klidně by to mohlo přenášet 100x více. Jediným omezením je tu rychlost úložiště a AWS S3 je na takové věci stavěné, takže limitu není zrovna snadné dosáhnout.
Nejzajímavější na tom ale je, že celá akce vyšla na necelý dolar. Navíc nebylo potřeba nic domlouvat, nakupovat hardware atd. - klik klik a najednou mám k dispozici 32 "serverů".
Alternativní řešení
Samozřejmě bych mohl celý problém i nějak obejít. Například v jednom regionu stáhnout data (třeba po eshopech), zabalit, přenést, rozbalit, uploadovat. Až tak zásadní rozdíl by v tom ale asi nebyl, ale hlavně bych vám na tom nemohl předvést toto řešení. Úplně stejný postup se totiž používá třeba pro analytiku. Potřebujete vyhodnotit obrovské množství dat, tak je rozdělíte na menší celky, vyřešíte distribuci práce, sbírání výsledků a pošlete na to stádo instancí. Stejně tak třeba při převodu 100TB videí do jiného formátu. Nebo třeba při skenování internetu (což teda zrovna AWS nepovoluje).Další díly:
- Proč jsme migrovali do cloudu Amazonu (AWS)
- Cloud na český způsob
- Jak na AWS cloud - první kroky
- AWS cloud za hubičku! - první server, úspory a load balancer
- Vychytávky v Amazon cloudu
- Jak se programuje v cloudu
Update: Nestačí vám články? Nově nabízím i konzultace AWS cloudu :)
