Jak si vyrobit "New Relic" na koleni
Nedávno jsem tu dlouze popisoval, jak nemáte vymýšlet kolo a dneska si ukážeme, jak se takové kolo vymýšlí. Potřeboval jsem sledovat konkrétní údaje o výkonnostních mezerách v našich eshopech a New Relic na to nestačil, takže jsem si musel vyrobit vlastní.
Co je New Relic?
New Relic je udělátko, které si nainstalujete na server a dělá vám krásné reporty o výkonu. Může například poslat email, když rychlost webu klesne pod stanovenou hranici nebo s ním snadno najdete slabá místa, které si zaslouží optimalizaci. Je to velmi chytrý nástroj, který má ale špatně postavený ceník.Platí se za server bez ohledu na to, jestli je to server s osmi procesory a 256GB RAM nebo cloudová instance s jedním virtuálním jádrem. V našem případě bychom tak platili za provoz jedné instance Amazonu $28 měsíčně a New Relicu za její monitoring $149 měsíčně. Instancí běží vždycky více, takže to jsou desetitisíce korun měsíčně za monitoring a to se úplně nevyplatí.
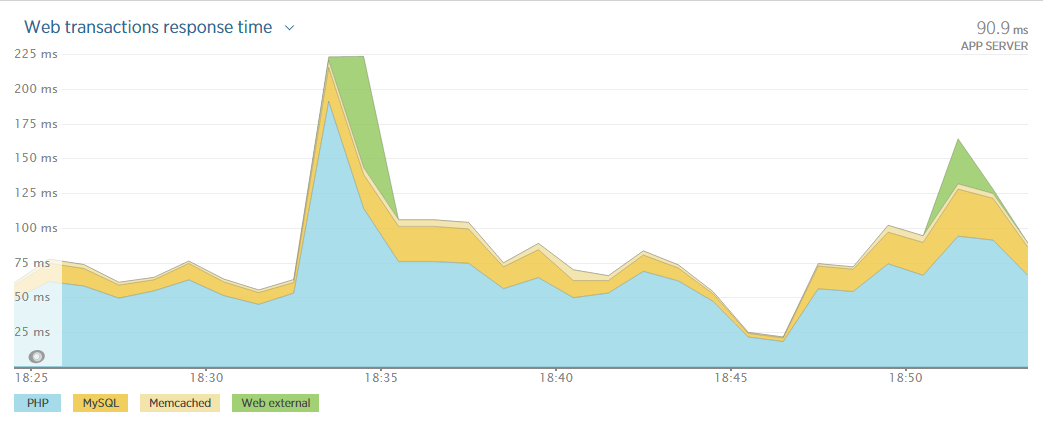
Co budeme měřit?
U eshopů bych potřeboval mít přehled o komunikaci s databází. Pokud například eshop s deseti produkty potřebuje na vypsání hlavní strany 200 dotazů, je nejspíš něco špatně. Pokud při výpisu kategorie jeden dotaz trvá déle než všechny ostatní dohromady, je také asi něco špatně. Chtěl bych mít o takových situacích přehled, aby se mohly prověřit a případně optimalizovat.Problémy měření
Před implementací je potřeba zohlednit několik rizik:Decentralizace
Eshopy běží paralelně z více serverů a ty se navíc různě zapínají a vypínají (a zahazují). Data se tudíž musí ukládat do nějakého centrálního úložiště.Rychlost
Měření nesmí nijak brzdit provoz webu. Je zbytečné lovit milisekundy optimalizací, když by samotné měření brzdilo každé načtení stránky třeba o 50 ms. To nám trochu komplikuje ukládání do centrálního úložiště, protože komunikace po síti by brzdila web. Podobný problém má lokální databáze i zápis do souborů.Vysoký průtok a paralelní zápis
Budeme evidovat každé načtení stránky i všechny související požadavky (třeba každé písmenko v autocompletu). To znamená ukládání milionů událostí denně. Pokud chceme vyhodnocovat dlouhodový vývoj, tak databáze může mít po roce úplně hravě miliardu řádků.Server navíc vyřizuje paralelně vždy několik požadavků a ty na sebe nesmí čekat. Zápis informace, tak musí být možný paralelně.
Dostupnost
Pokud by s ukládáním byl nějaký problém (například nedostupné/přetížené úložiště), tak to nesmí mít vliv na provoz webu. Evidování informací o generování stránky nemá přednost před návštěvníkem.(Ne)řešení s Amazonem
V Amazonu se výše popsané problémy řeší snadno. Pro zápis událostí má připravenou službu Kinesis. Do té můžete zapisovat libovolnou rychlostí a poradí si s tím. Je navíc optimalizovaná pro takové použití, takže komunikace má minimální režii - pod 1 ms. Kinesis pak funguje jako fronta/buffer - sbírá události z libovolného množství zdrojů a vy si je z druhé strany můžete svým vlastním tempem klidně třeba jen jednou za hodinu vyzvednout a zpracovat. Z Kinesis bych pak data převáděl do Redshift. To je databáze určená na zpracování velkého množství dat - bez mkrnutí zvládne uchovávat/zpracovávat petabajty dat.Říkal jsem ale, že budeme vymýšlet kolo, takže nebudu používat hotové řešení. Provoz Kinesis+Redshift navíc něco stojí a já chci naopak ušetřit.
Získání dat
Pro začátek bych chtěl zjišťovat počet dotazů na stránce, celkovou dobu trvání, počty/trvání podle typu dotazu (select/update/insert/delete), o jaký typ stránky šlo (frontend, import zboží, ...), který eshop a o jakou stránku šlo (hlavní strana, výpis kategorie, ...). Jako nejnižší vrstvu pro práci používáme dibi a tam to jde realizovat poměrně snadno:<?php
// maximálně zjednodušeno - v reálu to asi budete chtít řešit jinak
class SqlEvent {
public static $time = 0;
public static $count = 0;
}
$connection = new DibiConnection(...);
$connection->onEvent[] = function (DibiEvent $event) {
if($event->type & \DibiEvent::QUERY) {
// pro začátek počítáme všechny typy dotazů dohromady
SqlEvent::$count++;
SqlEvent::$time += $event->time * 1000;
}
};
register_shutdown_function(function () {
$sock = socket_create(AF_INET, SOCK_DGRAM, SOL_UDP);
$message = json_encode([
'shop' => 'jadi',
'host' => $_SERVER['HTTP_HOST'],
'time' => time(),
'type' => 'frontend',
'route' => 'Index',
'queries' => SqlEvent::$count,
'duration' => SqlEvent::$time,
]);
socket_sendto($sock, $message, strlen($message), 0, '127.0.0.1', 10360);
socket_close($sock);
});
V onEvent dibi říkáme, aby nám počítala dotazy a jejich celkové trvání a aby se počítaly jenom select/update/insert/delete. Rovnou tady můžeme evidovat i každý typ dotazu zvlášť.
Nejzajímavější je odesílání dat. Všimněte si, že používám UDP socket. Ten má zásadní výhodu, že nebude nijak brzdit aplikaci. Odešlu data události a nečekám na odpověď. Pokud navíc nebude cílový server dostupný, tak to nic nezpůsobí - stejně nečekáme na odpověď, takže nedostupnost nijak neovlivní dostupnost/rychlost webu. Díky tomu jsme odstranili problém s pomalou síťovou komunikací a klidně by sběr dat mohl běžet na jiném serveru.
Zjevnou nevýhodou je, že se data z měření můžou snadno ztrácet. S takovým rizikem ale počítáme a není v tomto případě problémem.
Sběr měřících dat
Data úspěšně odesíláme, ale ještě je musí něco přijímat. Na to si vyrobíme primitivní UDP server v Node.js. Proč zrovna v Node.js? Protože to v něm budu mít hotové za 5 minut a navíc by nemělo mít problém s paralelními požadavky.var dgram = require("dgram");
var server = dgram.createSocket("udp4");
var batchSize = 200;
var bigQuery = require('bigquery');
bigQuery.init({
client_email: '------@developer.gserviceaccount.com',
key_pem: 'key.pem'
});
var messageBuffer = [];
server.on("message", function (rawMessage) {
var message = JSON.parse(rawMessage.toString('utf8', 0));
messageBuffer.push({json: message});
if (messageBuffer.length > batchSize) {
bigQuery.job.load('shop', 'sql', 'sql' + (new Date()).toISOString().substring(0, 10).replace(/-/g, ''), messageBuffer.splice(0, batchSize), function (e, r, d) {
if (e) console.log(e);
console.log(JSON.stringify(d));
});
}
});
server.bind(10360);
Server už ani nemůže být jednodušší. Poslouchá na UDP portu 10360. Příchozí zprávu dekóduje jako JSON a uloží do pole. Pokud už je v poli víc jak 200 záznamů, tak je vezme a odešle jako dávku do Google BigQuery. Nejsložitější částí kódu tak je vytvoření názvu tabulky v BigQuery, protože chceme pro každý den mít samostatnou tabulku (v BigQuery se s tím pak lépe pracuje).
Pokud by se server restartoval před odesláním dávky, tak se data (max 199 záznamů) ztratí. S tím počítáme a ani se to nevyplatí řešit.
Google BigQuery
Google BigQuery je služba určená přesně na podobné využití - v principu je to podobné jako AWS Redshift, ale mnohem jednodušší. Můžete do ní ukládat obrovské množství dat a nad nimi pak provádět dotazy. Data ale nejdou zpětně nijak měnit nebo mazat (jen celé tabulky). Je to proto ideální na využití jako tady - ukládání dat logů, které chcete nějak zpracovat.Nejzajímavější na tom pro nás je, že počítá se zpracováním alespoň terabajtů dat, takže v našich objemech funguje téměř zadarmo.
Pokud budete BigQuery zkoušet, tak si založte dataset v US a ne v EU. Vývoj BigQuery totiž zamrznul někdy v roce 2013, takže například novinkové streamované vkládání záznamů, které tu používám, je dostupné jen v US a do EU už se nedostalo.
Vyhodnocování dat
Sbíráme data, krásně je ukládáme, takže bychom mohli vytvořit i nějaký výstup. Ideální by bylo propojit BigQuery s Excelem. Google sice vytvořit v roce 2012 konektor, ale ten je přinejlepším kostrbatý - vygenerovat si tabulku dat na webu BigQuery a zkopírovat ji do Excelu je rychlejší, než řešit konektor. Čekali byste, že bude mít alespoň propojení na svůj vlastní Spreadsheet a skutečně má - pokud vám ovšem nevadí napsat si nejdřív 200 řádkový skript.Komunikace z PHP přes API taky není zrovna výhra. Ušetřím vám dvě hodiny času - zkopírujete následující funkci a na nic se neptejte. Věřte mi, že nechcete víc vědět.
<?php
function getData($sql) {
$credentials = new \Google_Auth_AssertionCredentials(
'---------@developer.gserviceaccount.com',
[\Google_Service_Bigquery::BIGQUERY],
file_get_contents(__DIR__ . '/google.p12')
);
$config = new \Google_Config();
$config->setCacheClass('Google_Cache_Apc');
$client = new \Google_Client($config);
$client->setApplicationName('app');
$client->setAssertionCredentials($credentials);
if($client->getAuth()->isAccessTokenExpired()) {
$client->getAuth()->refreshTokenWithAssertion($credentials);
}
$bigQuery = new \Google_Service_Bigquery($client);
$job = new Google_Service_Bigquery_Job();
$config = new Google_Service_Bigquery_JobConfiguration();
$queryConfig = new Google_Service_Bigquery_JobConfigurationQuery();
$queryConfig->setQuery($sql);
$queryConfig->setPriority("INTERACTIVE");
$config->setQuery($queryConfig);
$job->setId(md5(microtime()));
$job->setConfiguration($config);
$running = $bigQuery->jobs->insert('shop', $job);
/* @var $running Google_Service_Bigquery_Job */
$jr = $running->getJobReference();
$jobId = $jr['jobId'];
$res = $bigQuery->jobs->getQueryResults('shop', $jobId);
$data = [];
foreach ($res as $r) {
$row = [];
foreach ($r->getF() as $column) {
$row[] = $column->v;
}
$data[] = $row;
}
return $data;
}
Grafíky!
Máme data, umíme je vyhodnotit, tak si konečně uděláme grafík.<?php
$typePieDuration = [['Type', 'Duration']];
foreach (getData("SELECT type,sum(duration) dur
FROM (TABLE_DATE_RANGE(sql.sql,DATE_ADD(CURRENT_TIMESTAMP(), -1, 'DAY'),CURRENT_TIMESTAMP()))
where time>DATE_ADD(CURRENT_TIMESTAMP(), -1, 'DAY')
group by type order by dur LIMIT 10000") as $r) {
$typePieDuration[] = [$r[0], round($r[2])];
}
echo '<script> var pieData = '.json_encode($typePieDuration).';</script>';
?>
<div id="pie"></div>
<script type="text/javascript" src="https://www.google.com/jsapi?autoload=%7B%22modules%22%3A%5B%7B%22name%22%3A%22visualization%22%2C%22version%22%3A%221.0%22%2C%22packages%22%3A%5B%22corechart%22%5D%7D%5D%7D"></script>
<script>
var pie = document.getElementById('pie');
(new google.visualization.PieChart(pie))
.draw(google.visualization.arrayToDataTable(pieData), {'title': 'Trvání SQL podle typu (den)'});
</script>
To už jsou klasické Google Charts a jeden SQL dotaz do BigQuery. Všimněte si, jak je klauzule FROM dynamická - vybírá se totiž z posledních dvou tabulek, protože každý den se zapisuje do nové. A takhle vypadá výsledek:
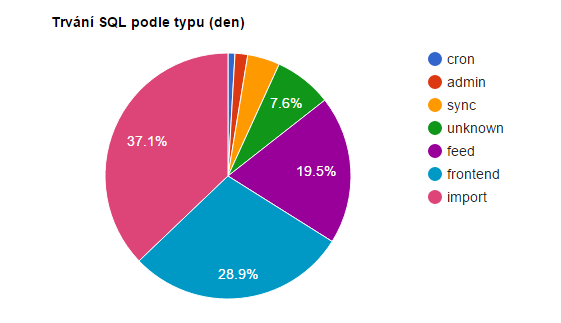
To je reálný výstup z našich eshopů za posledních 24 hodin. Krásně z něj vidím, že s ShopAPI jdeme správným směrem a u importů zboží máme prostor k optimalizaci. Kromě toho samozřejmě můžu dělat graf třeba průběhu vývoje poměru během dne nebo sledovat konkrétní importy, které vytváří zátěž.
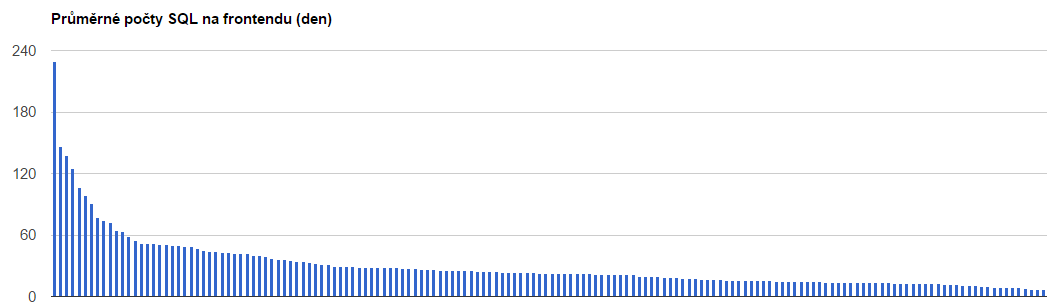
Další graf je průměrný počet dotazů na vykreslení stránky podle eshopů. Krásně z toho vidím, že je tam 10-15 eshopů, na které se vyplatí podívat. Samozřejmě může být samotný údaj o počtu dotazů zavádějící, ale rovnou to můžu kombinovat s dalšími výstupy a velmi rychle najít problém.
BigQuery ale zvládá víc než obyčejné dotazy s jednou podmínkou. Má totiž už rovnou připravené různé statistické funkce, takže s vhodnými daty lze přímo zjišťovat podezřelé události nebo změny trendů a reportovat je třeba na email. Ale o tom zase jindy.
Uff... a to je všechno. Taky jste čekali, že udělat si vlastní monitoring dá více práce? Příště bych se ale asi nepoužil Google - sice provoz nic nestojí, ale drbání se s detaily za tu úsporu nestálo.
EDIT: Z komentářů doplňuji tip od Pavla Jaška na plugin OWOX BI BigQuery reports - ten umožňuje velmi jednoduché propojení Spreadsheets a BigQuery, takže se pak při vizualizaci nemusíte drbat s ručním propojováním.
Update: Nestačí vám články? Nově nabízím i konzultace AWS cloudu :)
